
The word “cobot” denotes a robot optimised for the collaboration with humans. Traditional industrial robotics guarantees high efficiency and repeatability for mass production but it lacks flexibility to deal with the fast changes in the consumers’ demand. Humans, on the other hand, can face such uncertainties and variability but they are limited by their physical capabilities, in terms of repeatability, physical strength, endurance, speed etc. The human-robot collaboration is a productive balance that catches the benefits from both industrial automation and human work.
In traditional automation, decisions are frequently driven by PLC logics. In discrete manufacturing, the problem of how to choose when two or more possibilities are simultaneously available may arise.
Precedence rules are normally adopted. Sometimes, the definition of these rules is based on a priori knowledge of the system. Most often, they rely on intuition of the programmer who implements simple tie-breaking rules with no clear foundation in terms of optimality.
A static job scheduling determines which operations have to be executed by either the human or the robot in an a-priori way. This methodology can be useful when changes in the workplace are not observable, agent performance is not measurable and/or the system is observable and measurable but the agents are not controllable anymore once the task has begun.
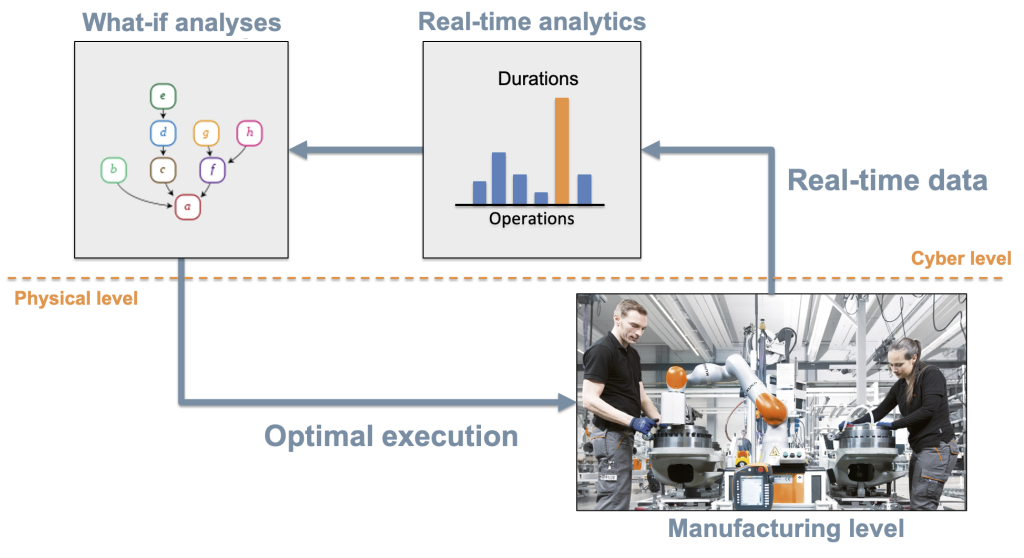
But how about allowing robots to learn optimal decisions from experience? … moreover, what if the robot can learn by running what-if analyses within a digitalised environment (i.e. a digital twin)?
By collecting production data from the physical system, the digital twin can progressively tune its parameters so to fit the actual behaviour of the system.
Based on these parameters, simulations or what-if analyses can be run to predict the effects of decisions, and select which decision will actually provide the best outcome in terms of performance or productivity. The key idea is sketched in the following.
Reinforcement learning is the process adopted to learn what to do (the policy) based on the experience. While typical demonstration of such a method relies on an initial trial-and-error phase on the real system, the approach of learning on the digital replica of the system has obvious advantages, including a faster learning rate.
In our Lab we run a series of verification tests in a collaborative human-robot assembly scenario. The product to be assembled is the Domyos Shaker 500 ml produced by Decathlon. The robot and the operator collaborate in assembly six identical products. Job allocation and job sequencing problems are dynamically optimised.
Below, a video of the application.
References:
- G. Fioravanti, D. Sartori, “Collaborative robot scheduling based on reinforcement learning in industrial assembly tasks”, MSc Thesis at Politecnico di Milano, 2020
- R. S. Sutton, A. G. Barto, “Reinforcement Learning: An Introduction”. MIT Press, 1998